Supply chain exceptions are not edge cases. In any logistics operation running at scale across multiple parties, collection failures, late arrivals, damaged goods, capacity shortfalls and documentation errors occur every day. The question is not whether they will happen but how quickly the right people find out and how efficiently the situation is resolved.
Most operations do not have a structured answer to either question. Exceptions are detected late, communicated by phone or email and resolved through a series of bilateral conversations between parties who each have an incomplete picture of what happened and limited visibility of the downstream consequences of any decision they make. The operational cost of this approach is significant and almost entirely invisible in standard management reporting.
What counts as a supply chain exception
An exception is any event that causes a shipment, order or warehouse operation to deviate from the planned state. The category is broader than most operations formally recognise.
Transport exceptions include missed collections, late deliveries, vehicle breakdowns, failed delivery attempts, incorrect addresses and documentation errors. Warehouse exceptions include short picks, damaged inbound goods, overbooked dock slots, inventory discrepancies and labour shortfalls that affect throughput. Carrier exceptions include capacity withdrawals, rate disputes and service failures that emerge mid-shipment. Customs and compliance exceptions include hold orders, incorrect commodity codes and missing certificates of origin.
Each of these events requires a decision and a response. Some require the involvement of multiple parties: the carrier, the warehouse, the shipper and sometimes the end customer. The cost of the exception is partly in the direct consequence, a re-delivery, a detention charge, a failed delivery promise and partly in the time spent identifying the exception, communicating it to the relevant parties and reaching a resolution. The second category of cost is where most operations lose the most ground.
“It’s really more of a blended assessment and analysis than just looking at that bottom line or that purchase order cost.”
Emma Stone, VP of Global Operations at Hurdle

The hidden cost of reactive exception handling
The operational cost of exceptions in logistics is routinely underestimated because it appears in the wrong reporting category. Detention charges appear as a transport line item. Re-delivery costs appear as a fulfilment cost. Failed delivery promises appear as customer service failures. The root cause, that the exception was identified too late or communicated too slowly to allow an effective response, rarely appears anywhere.
The pattern is consistent across operations of different sizes and sectors. A vehicle misses its collection window. The carrier's driver moves on to the next job. The warehouse is not notified. The shipper is not notified. When the shipment fails to arrive at the distribution centre on time, the first call goes from the DC manager to the transport team, who call the carrier, who reach the driver, who provides an approximate estimated time of arrival. By the time a decision can be made about whether to wait, re-route or re-plan the outbound load, the window for effective action has often already closed.
The pattern holds whether the exception is a transport failure, a warehouse capacity problem or a documentation error. Each step in the manual exception communication chain adds delay. Each delay reduces the options available by the time a decision is reached. What began as a resolvable delay becomes a missed delivery promise, a re-delivery cost and a customer service conversation that should never have been necessary.
We cover the structural relationship between coordination gaps and operational cost in our piece on logistics operations productivity.

Why exceptions are harder to manage across multiple parties
Single-entity operations, a company that owns its own warehouse, vehicles and drivers, can design exception management workflows within a single system and a single management hierarchy. When an exception occurs, the information is available to the people who need it and the decision authority is clear.
Multi-party operations do not have this advantage. In a supply chain where a shipper contracts a 3PL, which in turn contracts hauliers, and where goods move through warehouse facilities operated by different entities, each party manages exceptions within their own system. The exception data does not automatically flow to the other parties in the chain. It must be communicated, usually by phone or email, to each affected party individually.
This creates two problems. The first is speed: the exception must be communicated manually, and each communication adds delay. The second is completeness: the party communicating the exception shares the information relevant to their position in the chain but may not be aware of the downstream consequences. A carrier who reports a late vehicle does not know what the warehouse has booked into the affected slot, whether there is flexibility to accommodate the delay or what the shipper has committed to the end customer. The parties who have that information are not in the same conversation.
The coordination challenge in multi-party exception management is not primarily a technology problem. It is an information architecture problem. The relevant information exists across the network. The question is whether it can be assembled in one place, made visible to all affected parties simultaneously and used to drive a decision within the window where the decision is still useful.

Rupert Morrison
Strategy & Organisational Design Expert
Chain Reaction Podcasts
Designing Strategy That Delivers Results
Most logistics companies confuse activity with strategy. Rupert shows why organisational design — not just execution — determines whether strategic plans actually deliver results.
The detection gap: when exceptions become visible too late
In well-designed exception management processes, the goal is to detect the exception as early as possible, ideally before it causes a service failure rather than after. This requires visibility into the operation at the level of individual events: a vehicle departing outside its planned window, an inbound delivery arriving short of the manifest quantity, a driver reaching a delivery point outside the agreed time window.
Most operations detect exceptions at the point where they cause a visible failure, not at the point where they originate. A vehicle that departs the collection point 45 minutes late will likely cause a warehouse slot miss and potentially a downstream delivery failure. If that delay is visible in real time to the warehouse and the shipper, both parties have options: adjust the slot, notify the end customer, begin re-planning the outbound load. If the delay is only communicated when the vehicle fails to arrive, those options are no longer available.
The detection gap has two sources. The first is a technology gap: not all parties have systems that capture events in real time. A carrier without GPS tracking, or with tracking that does not integrate into any shared visibility layer, cannot communicate departure times automatically. The second is an integration gap: even where parties have systems that capture real-time data, those systems are not connected to the systems used by their partners in the supply chain.
Closing the detection gap requires integration at the network level, not just within each organisation. This is the argument for shared operational platforms rather than the bilateral point-to-point integrations that most multi-party supply chains rely on today. The broader pressure this creates in UK logistics specifically is covered in our piece on the UK logistics market state of play.

What structured exception management actually requires
Effective exception management is defined by three capabilities: early detection, multi-party notification and structured resolution.
Early detection means identifying the exception at the operational event level before it becomes a service failure. This requires real-time data capture at each step of the operation and a system that can compare the actual state of each shipment against the planned state and raise an exception flag when the two diverge. The standard operating procedures that govern how data is captured and verified at each stage of the operation matter directly here, because detection is only as reliable as the data flowing into the system. We cover this in our piece on logistics standard operating procedures.
Multi-party notification means that when an exception is detected, all affected parties are informed simultaneously through a common interface, not through a series of phone calls that each add delay. The notification must include the relevant context: what happened, where in the chain it occurred, which parties are affected and what the planned state was.
Structured resolution means that the options available to resolve the exception are presented to the decision-makers with the information they need to choose between them. This is a higher standard than notification alone. Notification tells parties that something has gone wrong. Structured resolution supports the decision about what to do next by making the relevant constraints, options and downstream consequences visible in the same interface where the exception is being managed.
Most operations have the first capability in partial form within individual organisations. Very few have the second or third in any form across multi-party networks. This gap is where the most recoverable cost in complex logistics sits.
Ask anything to learn how FLOX works and helps buyers and sellers of logistics run more efficient and profitable operations.
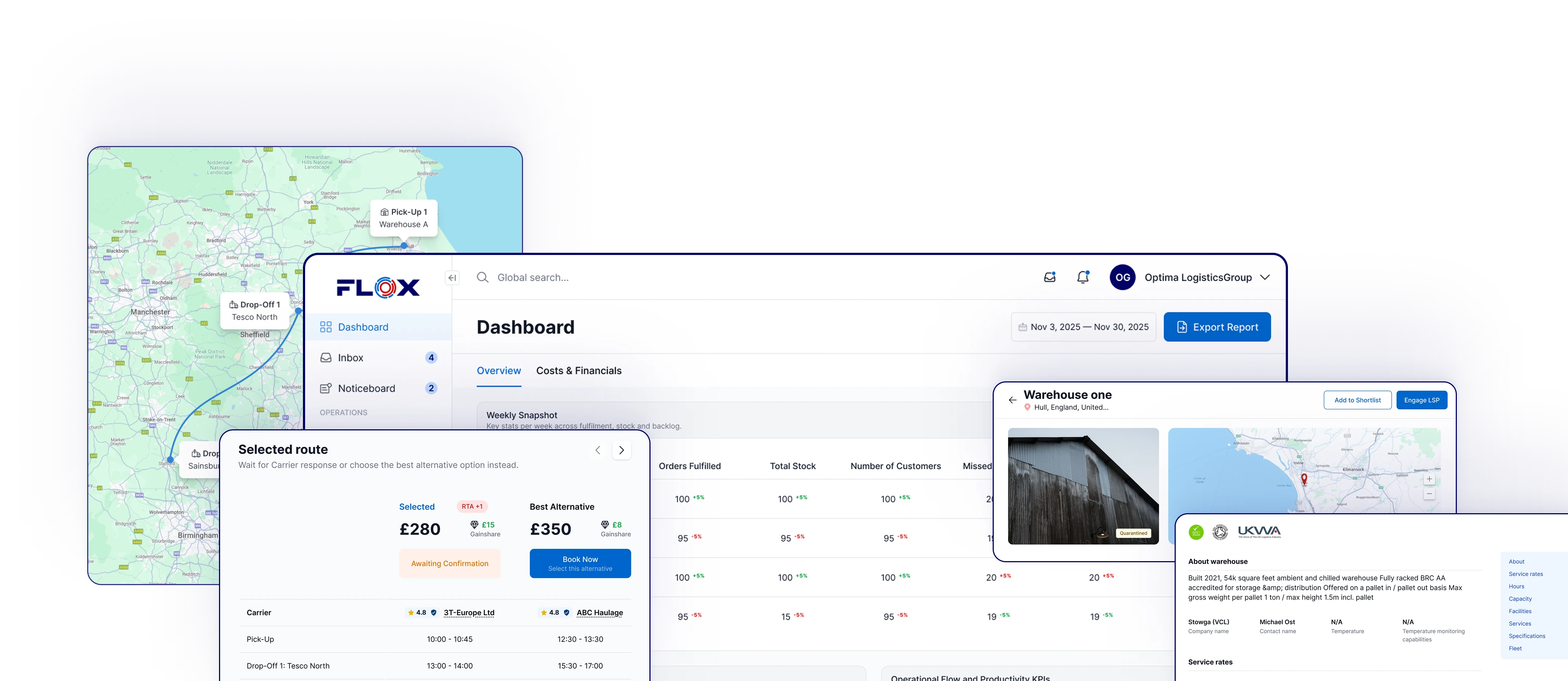
How FLOX approaches exception handling across the network
FLOX operates as a marketplace and orchestration platform. The marketplace layer connects shippers, 3PLs, warehouse providers and hauliers, making capacity available across the network. The orchestration layer coordinates execution across every shipment, including the detection and resolution of exceptions as they occur.
Within the orchestration layer, exceptions are raised at the event level across every party in the shipment. A missed collection, a short-pick at the warehouse or a failed delivery attempt is visible to all affected parties through the platform at the point it occurs, not at the point it is manually communicated. The parties who need to act on the exception can see the relevant operational context, the constraints, the options and the downstream consequences of each decision, within the same interface.
This changes the exception management dynamic in multi-party operations from a series of bilateral phone calls, each introducing delay and information loss, to a shared, structured process where the decision window is preserved and the information needed to make a good decision is available to the parties who hold it.
The speed dimension compounds this further. As customers expect next-day and same-day fulfilment, the window in which an exception can be resolved without becoming a broken delivery promise has narrowed considerably. We cover the relationship between speed expectations and coordination pressure in our piece on modern supply chain speed pressure. The operations that manage exceptions well are not those with the most sophisticated internal tools. They are those with the most connected networks.
Subscribe to our newsletter.
Stay up to date with practical insights and useful logistics content
FAQs
A supply chain exception is any event that causes a shipment, order or warehouse operation to deviate from its planned state. Examples include missed collections, late deliveries, short picks, damaged inbound goods, overbooked warehouse slots and documentation errors. Each exception requires a decision and a response. In multi-party supply chains, the cost of exceptions is determined largely by how quickly the right parties find out and how efficiently they can coordinate a resolution.